Rails on AWS: Do you need nginx between Puma and ALB?
When I set up Rails on AWS, I usually use the following pattern:
(CloudFront) → ALB → Puma
I was wondering: Is it always necessary to put nginx between the ALB and Puma server?
My theory behind not using nginx is that because it has its own queue (while the Classic Load Balancer had a very limited “surge queue”, the ALB does not have such a queue), it will help in getting responses back to the user (trading for increased latency) while hindering metrics used for autoscaling and choosing what backend to route the request to (such as Rejected Connection Count).
I couldn’t find any in-depth articles about this, so I decided to prove my theory (in)correct by myself.
In this test, the application servers will be running using ECS on Fargate ( platform version 1.4.0). It’s a very simple “hello world” app, but I’ll give it a bit of room to breathe with each instance having 1 vCPU and 2GB of RAM. I’ll be using Gatling on a single c5n.large instance (“up to 25 gigabits” should be enough for this test).
In this test, I wanted to try out a few configurations that mimic characteristics of applications I’ve worked on: short and long requests, usually IO-bound. A short request is defined as just rendering a simple HTML template. A long request is 300ms. The requests are ramped from 1 request/sec to 1000 requests/sec over 5 minutes.
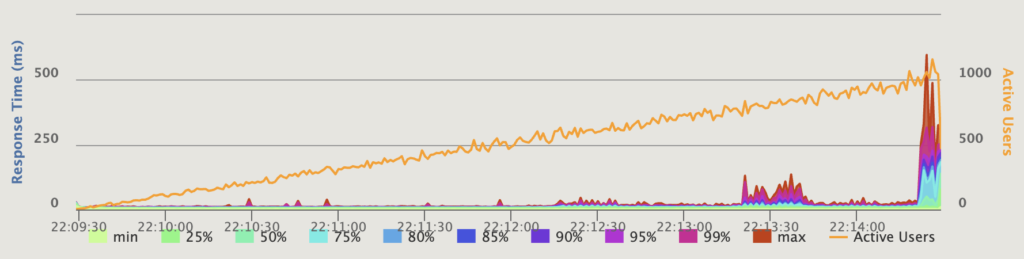 Response Time Percentiles over Time (OK responses), simple render — 4 instances, 20 threads each, connected directly to the ALB.
Response Time Percentiles over Time (OK responses), simple render — 4 instances, 20 threads each, connected directly to the ALB.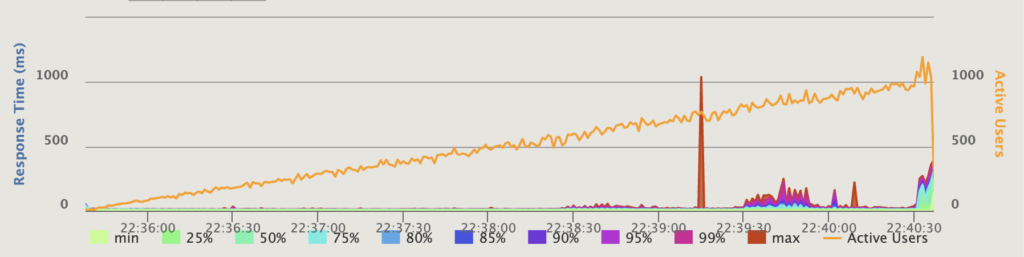 Response Time Percentiles over Time (OK responses), simple render — 4 instances, 20 threads each, using Nginx.
Response Time Percentiles over Time (OK responses), simple render — 4 instances, 20 threads each, using Nginx.
As you can see, for the simple render scenario, Nginx and Puma were mostly the same. As load approached 1000 requests/sec, latency started to get worse, but all requests were completed with an OK status.
The 300ms scenario was a little more grim.
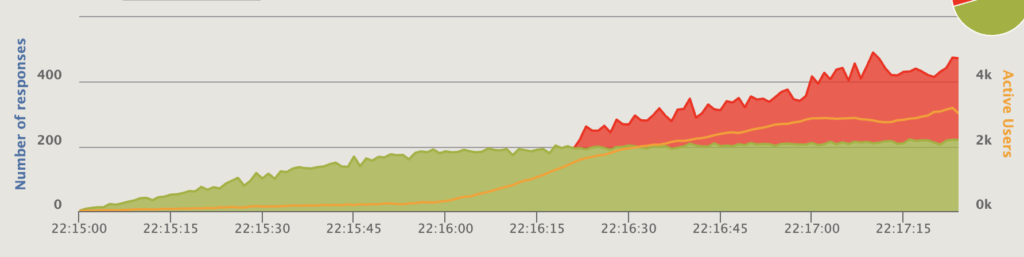 Number of responses per second (green OK, red error), 300ms response — 4 instances, 20 threads each, connected directly to the ALB.
Number of responses per second (green OK, red error), 300ms response — 4 instances, 20 threads each, connected directly to the ALB.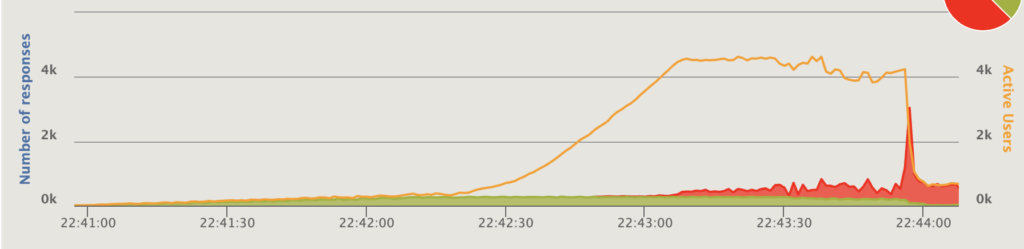 Number of responses per second (green OK, red error), 300ms response — 4 instances, 20 threads each, using Nginx.
Number of responses per second (green OK, red error), 300ms response — 4 instances, 20 threads each, using Nginx.
My theory that Puma will fail fast and give error status to the ALB when reaching capacity was right. The theoretical maximum throughput is 4 instances * 20 threads * (1000ms in 1 second / 300ms) = 266 requests/sec. Puma handles about 200 requests/sec before returning errors; Nginx starts returning error status at around 275 requests/sec, but at that point requests are already queueing and the response time is spiking.
Remember, these results are for this specific use case, and results for a test specific to your use case probably will be different, so it’s always important to do load testing tailored to your environment, especially for performance critical areas.