Audio Recognition in NodeJS
I live in a small town that occasionally broadcasts announcements over the radio. For the past few years, I’ve been building a small Raspberry Pi appliance to transcribe these broadcasts to text. However, there are many broadcasts that don’t contain spoken content, so I wanted a way to recognize the kind of broadcast and make a decision whether to send it to the speech-to-text service or not.
Here’s what I have right now:
flowchart LR
A(["Broadcast started"])
A --> E["Encode MP3"] & F["Google Cloud<br>Speech-to-Text"]
E --> G["Output MP3 to file"]
F --> H["Summarize text<br>with ChatGPT"]
H --> I["Send notification"]Our town has multiple notifications throughout the day: 6 AM, 10 AM, 12 AM, 3 PM, and 5 PM. Almost every day, there’s a broadcast at 6:30 PM with general information. However, there are other types of notifications that may be broadcast at any time during the day: ferries being cancelled, roads closed, other notifications that residents may be interested in.
The problem is that there are a lot of notifications that get recorded and streamed to the speech-to-text service even if it will never have spoken content in it — after a couple years, the poor little Raspberry Pi is getting full of MP3s of the exact same chime.
My Process
When getting started with this, I knew that I would need to use a Fast Fourier Transform to analyze the audio data. Aside from that, though, I didn’t really know what I would need. I knew that audio fingerprinting was a thing, so my relatively simple approach should be technically possible.
After a lot of chatting with ChatGPT, this is how I decided to create fingerprints:
- Split incoming data into 25ms windows with 10ms overlap. The overlap is required so we can match unaligned data.
- Run the FFT on the window.
- Convert the results of the FFT to power spectrum.
- Bin the frequencies from the FFT into Mel bins. (I currently use 20 bins, but I’m going to be experimenting with using less in the future)
- Convert the power energy values to log scale.
- Run a DCT on the Mel bins.
At this point, I’m pretty comfortable. All I need to do is store these 20-element vectors and then compare them with others, and I’ve done that before! A few years ago, I was working on a document similarity project, and it’s essentially the same. Once you have something vectorized, just run cosine similarity on it.
I’m still a beginner at Rust, so it took quite a bit of stumbling before it could compile, but once it did, it worked almost perfectly.
”almost”
It worked pretty well for 2 or 3 fingerprints in the database, but once I added more, it quickly returned a lot of false positives for other fingerprints. I thought that this may be because of silence between notes or similar notes matching in different sections of the audio.
I decided to test this theory by widening the comparison window — this time to about 1 second. It worked a lot better, which means I was definitely getting somewhere. However, widening the comparison window to 1 second means that I can’t get a match result until 1 second after the audio started playing — way too long.
So, I decided to clip the fingerprints down to very short clips with as little silence as possible — 1 or 2 seconds. The comparison logic will continue as normal, and I’ll use an algorithm that takes into account consecutive matches as well.
Integration
OK — now, everything is technically working. I have test files and they are performing the way I expect them to. I wrote this in Rust, because it’s eventually going to be running on a Raspberry Pi, and it probably wouldn’t have run nicely if written in pure JavaScript (the language the appliance is written in).
Time for integration.
Before starting this project, I did some light research, found Neon, and wrote a simple “Hello World” module written in Rust that provides an interface to NodeJS. So, now it was time to put everything above into Neon and provide a nice JavaScript interface.
It wasn’t as easy as I thought it would have been.
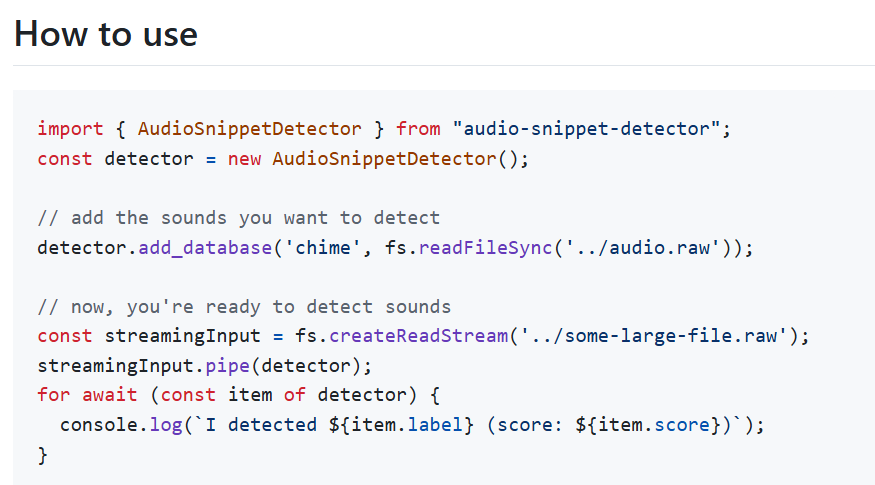
First, I wanted to implement this module as a Writable stream, so it could be hooked into my existing pipe solution. I also wanted to get events from the module as an Async Iterator. Initially, I tried to implement the interface entirely in Rust using Neon, and that didn’t go well at all. Creating classes is almost impossible.
I ended up writing the bare minimum in Rust: an initialization function that returned a context object, and other functions that took that context with other arguments. Then, I created a TypeScript connector to adapt the interface to be more ergonomic to the JavaScript ecosystem.
Next steps
Now that I’ve gotten everything built up, I now have to integrate it with the rest of the pipeline (keichan34/auto-streaming-stt — hosted here if you’re interested).
I’m currently working with getting it cross-compiled and published to NPM using GitHub Actions. I’ll probably write another post about that process once it’s up and running.
Conclusion
All in all, this was a very enjoyable foray into signal processing and writing a native NodeJS module. I’ve always been interested in native modules for intrepreted languages, and I think Rust is a good fit because of its performance characteristics and ecosystem. Even though integration was pretty tedious, it was by far the easiest I’ve ever experienced writing a native module.
I’m glad that I now have another tool in my toolbelt, and my experience with Rust has advanced another step.
Here’s the repository: keichan34/audio-snippet-detector. Feel free to check it out, and if you have any suggestions, I’d love to talk about them in an issue.