My wife Naoko wrote a reply to this post. It was fun comparing how different the podcasts we listen to are. :)
First, I’d like to plug a podcast that I’m a semi-regular guest on, techsTalking(5417), a podcast where technology people just talk about whatever is on our mind.
Here are some other podcasts that I’m currently subscribed to:
The Incomparable -- a podcast about anything geeky. Star Wars? Check. Star Trek? Check. Silly drafts? Check. Crazy movies? Check.
The Incomparable Game Show -- born from The Incomparable proper, regular panelists play crazy games for your entertainment. On the podcast.
Incomparable Radio Theater -- The Incomparable podcast, once upon a time, liked to do funny things on April Fools. Like, say: release a full-length episode in the format of old-time radio drama. Including equally funny sponsors (some fake, some real). Now, they’ve spun it off in to a separate podcast.
Random Trek -- Incomparable regular Scott McNulty hosts a podcast with non-random guests talking about random episodes of Star Trek.
As you may know, I am a big PostgreSQL user and fan. I also use Homebrew to manage 3rd party software packages on my Mac. PostgreSQL 9.4 was just released a couple days ago with some really cool features – a binary-format JSON datatype for speed and flexibility (indexes on JSON keys? Of course.), and some really good performance improvements. Read the release blog post and release notes for more information.
Kerbal Space Program -- KSP for short – is an incredibly addictive game about… Space exploration! In the game, you are in charge of the space program on planet Kerbin. Kerbin is located in a solar system quite similar to our own solar system, with a few differences. I’ve been playing this game for a few months, and finally decided to write a blog post about my experiences and thoughts.
If you aren’t familiar with Marshal.dump and Marshal.load, you probably should be. It’s used to serialize Ruby objects into binary data - mostly caching.
my_data =Rails.cache.fetch('an_object') doMyData.where(condition: 1).includes(:user).first
endmy_data.user
# On cache miss:# => SELECT "my_datas".* FROM "my_datas" WHERE "condition" = 1 ORDER BY "id" ASC LIMIT 1# => SELECT "users".* FROM "users" WHERE "id" = 1# On cache hit:# => SELECT "users".* FROM "users" WHERE "id" = 1
So, I wrote a quick module to make Marshal.dump and Marshal.load dump and load the association data, as well.
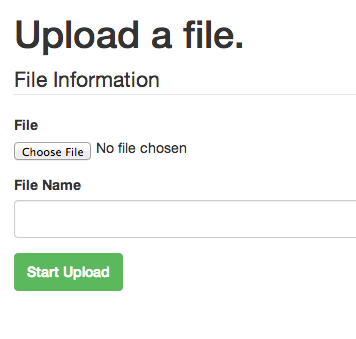
There have been more than a few times where someone needs to send a big file to me. So, I made a quick and dirty tool to allow anyone to upload files directly to a S3 bucket.
No more shuffling links around, worrying about them expiring, and wondering whether the data stored is safe or not.
Rubinius is an implementation of the Ruby language spec. I’ve been using it recently for a project, and I’ve been liking it so far. Here’s a few thoughts I’ve been having while using it.
Philosophy
The Core
Rubinius, in its core, is written in C++ and uses LLVM (Low Level Virtual Machine). Without getting too technical, it translates the Ruby code that you write into efficient machine code, then executes the machine code directly on the CPU. This architecture is very similar to Google’s V8 (and one of the reasons that Google Chrome is a fast browser).
There’s a Japanese word I like, “謎” - the dictionary defines it as “a mystery”, “riddle”, or “enigma” - I like to define it as “something that makes no logical sense whatever”.
Here is a part of WordPress that I think makes no logical sense whatever.
Inconsistent Naming Convention
In The Loop, as WordPress likes to call it, you are given some functions that will output information for you. Handy!