There have been multipleanalyses about the recent (2020/11/25) outage of AWS Kinesis and its cascading failure mode, taking a chunk of AWS services with it – including seemingly unrelated Cognito – due to dependencies hidden to the user. If you haven’t read the official postmortem statement by AWS yet, go read it now.
There are an infinite amount of arguments that can made about cascading failure; I’m not here to talk about that today. I’m here to talk about a time a few years ago I was evaluating a few systems to do event logging. Naturally, Kinesis was in consideration, and our team interviewed an AWS Solution Architect about potential design patterns we could implement, what problems they would solve, what hiccups we may encounter on the way, et cetera.
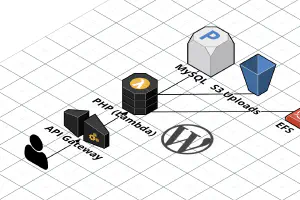
I previously wrote a post about running WordPress on AWS Lambda, but it was before EFS support was announced (EFS is a managed network file system AWS provides). Being able to use EFS completely changes the way WordPress works in Lambda (for the better!), so I felt it warranted a new blog post.
In addition, this time I’m using Terraform instead of SAM. This matches the existing infrastructure-as-code setup I use when I deploy infrastructure for clients. Here’s the Terraform module ( source code).
When I set up Rails on AWS, I usually use the following pattern:
(CloudFront) → ALB → Puma
I was wondering: Is it always necessary to put nginx between the ALB and Puma server?
My theory behind not using nginx is that because it has its own queue (while the Classic Load Balancer had a very limited “surge queue”, the ALB does not have such a queue), it will help in getting responses back to the user (trading for increased latency) while hindering metrics used for autoscaling and choosing what backend to route the request to (such as Rejected Connection Count).
I’m a big fan of AWS ECS Fargate. I’ve written in the past about managing ECS clusters, and with Fargate – all of that work disappears and is managed by AWS instead. I like to refer to this as quasi-serverless. Sorta-serverless? Almost-serverless? I’m open to better suggestions. 😂
There are a few limitations of running in Fargate, and this blog post will focus on working around one limitation: there’s easy way to get an interactive command line shell within a running Fargate container.
Throughout these past 4 years since AWS ECS became generally available, I’ve had the opportunity to manage 4 major ECS cluster deployments.
Across these deployments, I’ve built up knowledge and tools to help manage them, make them safer, more reliable, and cheaper to run. This article has a bunch of tips and tricks I’ve learned along the way.
Note that most of these tips are rendered useless if you use Fargate! I usually use Fargate these days, but there are still valid reasons for managing your own cluster.