Hosting a Single-Page App on S3, with proper URLs
Note (2019/07/05): I’ve posted a follow-up to this post about limitations about the technique used here, especially when hosting an API on the same domain.
Amazon S3 is a great place to store static files. You might want to even serve a single-page application (SPA) written in JavaScript there.
When you’re writing a single-page app, there are a couple ways to handle URLs:
A) http://example.com/#!/path/of/resource
B) http://example.com/path/of/resource
A is easy to serve from S3. The server only sees the http://example.com/ part, and so it serves that file to everyone.
B, however, is a little tricky. Single-page apps usually use pushState or replaceState to change the current URL without reloading, but once you reload (or give the URL to someone else) — BAM! You’ll get presented with a 404 Not Found error.
So why don’t we just use A? There are quite a few advantages to using B, over just being more elegant than putting that pesky #! in there. In my opinion, the biggest advantage of using B is that you’ll be able to make backend changes in the future without having to redirect URLs. For example, as your app gets bigger, you want to render some (or all) components server-side (see Isomorphic or Universal JavaScript).
To implement the B strategy, we need to serve the same index.html file to any URL requested by the client. As I mentioned earlier, we can’t do this with S3 itself, so we’ll enlist the help of CloudFront.
First, create a CloudFront distribution for the S3 bucket. Since CloudFront caches items for quite a long time, you might want to either set Cache-Control headers on your S3 files, or set the default TTL to something short, like a few seconds, in the CloudFront distribution settings. Once everything is set up (and you can access index.html by itself), click the “Error Pages” tab.
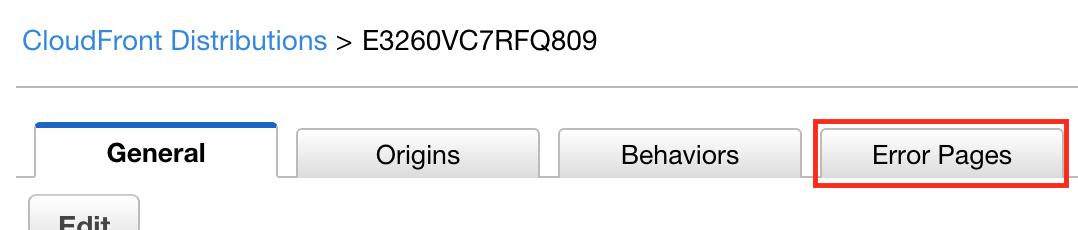
Click the big blue button, “Create Custom Error Response”:
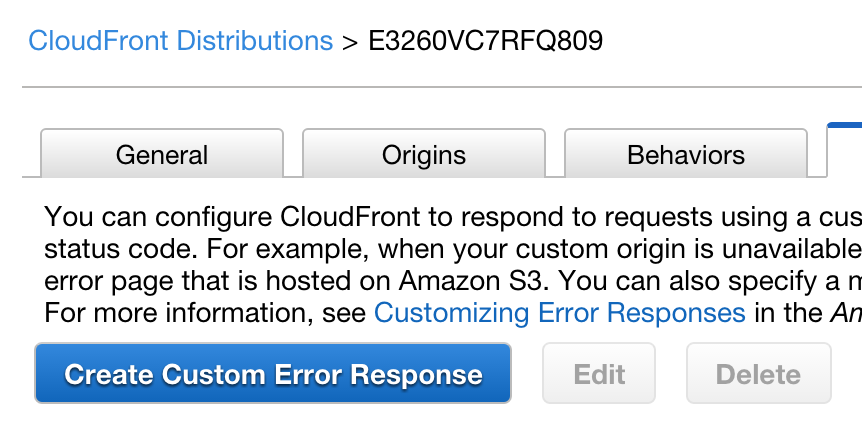
Now, I think you can tell what I’m up to now. Enabling “Customize Error Response” allows you to change a 404 from the backend (in this case, S3) in to a 200! Note that S3 will return a 403 response if you use the “S3 Origin” option instead of the S3-hosted origin. If you’re getting a 403 error from S3, customize the 403 error as well.
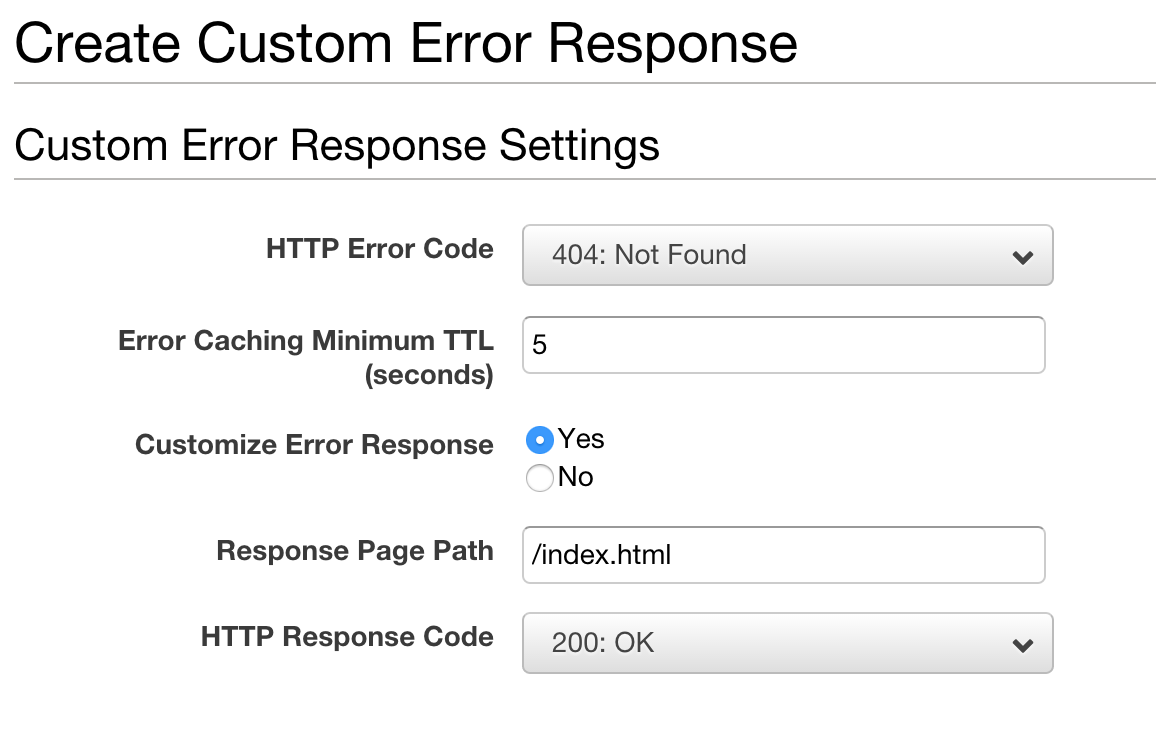
You can try out this setup below:
These all serve the same index.html. If you inspect the headers, the first link should be X-Cache: RefreshHit from cloudfront or Miss from cloudfront. However, if you look at the other requests, it will be X-Cache: Error from cloudfront. The status returned, however, is 200 — just as we wanted it.
Any questions? Contact me or leave a comment in the box below.