This year, I really wanted to work on my output, and I think I’m doing pretty well. Here are some things that I’ve been publishing:
Regular monthly blog posts on yakushima.blog A few posts this year on the Geolonia blog for work However, updates on this personal blog has been not so great – the previous post is the “2023 review” post, after all.
I’ve been updating this blog from 2012, when we officially incorporated Flagship.
I’m a big fan of AWS ECS Fargate. I’ve written in the past about managing ECS clusters, and with Fargate – all of that work disappears and is managed by AWS instead. I like to refer to this as quasi-serverless. Sorta-serverless? Almost-serverless? I’m open to better suggestions. 😂
There are a few limitations of running in Fargate, and this blog post will focus on working around one limitation: there’s easy way to get an interactive command line shell within a running Fargate container.
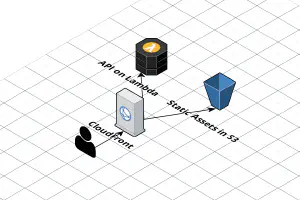
I’ve written about how to host a single page application (SPA) on AWS using CloudFront and S3 before, using the CloudFront “rewrite not found errors as a 200 response with index.html” trick.
Recently, working on a few serverless apps, I’ve realized that this trick, while quick, isn’t perfect. The specific case where it broke down was when the API is configured as a behavior on CloudFront (I usually scope the API to /api on the same domain as the frontend, so CORS and OPTIONS requests aren’t necessary).
Update 2020/07/29: AWS recently announced EFS support for Lambda, which makes running WordPress in Lambda easier, with fewer limitations. Here’s the new article about how to run WordPress in Lambda using EFS.
There are a few ways to run WordPress “serverless” on AWS. I’m going to talk about running WordPress on Lambda for this article. If you’re interested in how you can run WordPress serverless-ly on Fargate, I’m working on a post about that too.
Throughout these past 4 years since AWS ECS became generally available, I’ve had the opportunity to manage 4 major ECS cluster deployments.
Across these deployments, I’ve built up knowledge and tools to help manage them, make them safer, more reliable, and cheaper to run. This article has a bunch of tips and tricks I’ve learned along the way.
Note that most of these tips are rendered useless if you use Fargate!
The bots should announce, “I’m not a person, or if I am, I’m not allowed to act like one.”
Or, if there’s no room or time for that sentence, perhaps a simple bot at the top of the conversation. That way, we can save our human emotions for the humans who will appreciate them.
-- Truth in bots | Seth’s Blog
“If you can’t tell the difference, does it matter?
Update: Target tracking scaling is now available for ECS services.
I’ve been working on setting up autoscaling settings for ECS services recently, and here are a couple notes from managing auto-scaling for ECS services using Terraform.
min_capacity and max_capacity must both be set. schedule uses the CloudWatch schedule expression syntax, with the addition of the at(...) expression. Creating multiple scheduled actions at once Terraform will perform the following actions: + aws_appautoscaling_scheduled_action.
I’m currently working on migrating a Rails application to ECS at work. The current system uses a heavily customized Capistrano setup that’s showing its signs, especially when deploying to more than 10 instances at once.
While patiently waiting for EKS, I decided to use ECS over manage my own Kubernetes cluster on AWS using something like kops. I was initially planning on using Lambda to create the required task definitions and update ECS services, but native CodePipeline deploy support for ECS was announced right before I started planning the project, which greatly simplified the deploy step.
A few years ago when I was doing client work, we would regularly host clients’ sites and apps for them. During this time, I was responsible for both development and keeping them up and running as much as possible. Most of the money being in new development, it was difficult to assign priority to improving the operations of existing applications. In this period, I wanted an “operations person” to teach me how to make new applications that would need minimal operations support from the beginning.