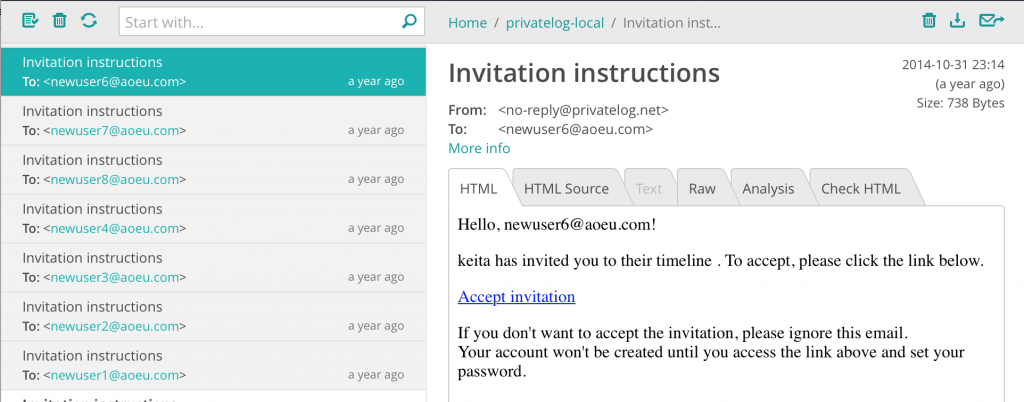
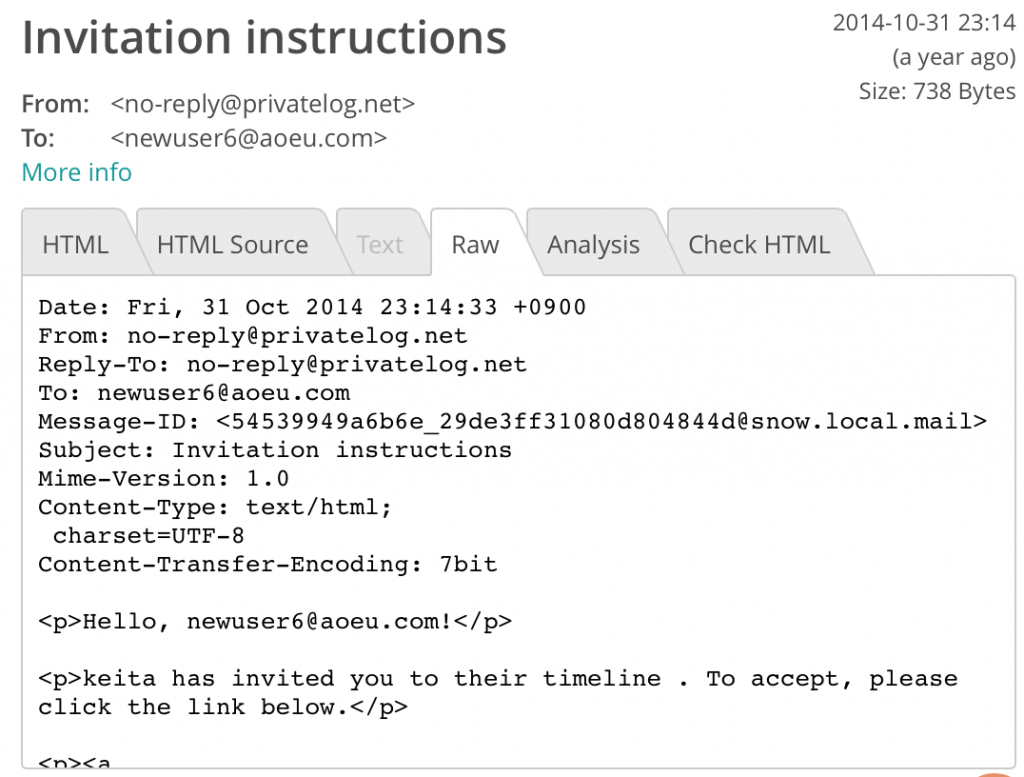
I’m a big Let’s Encrypt fan. They provide free SSL certificates for your web servers so you can protect the traffic from prying eyes. In fact, the connection between your web browser and my blog server is made private thanks to Let’s Encrypt.
Using Let’s Encrypt requires some setup and automation on your part if you want to use it in the AWS cloud, but AWS recently launched something called the AWS Certificate Manager or “ACM”. ACM takes care of issuing, renewing, and provisioning certificates for you — which is great because uploading SSL certificates to CloudFront and Elastic Load Balancers is not the most fun thing to do. I would pay for this, but Amazon has decided to give it to everyone for free. 🙂
As with anything AWS, this has a couple catches, but if you run your cloud resources in AWS you probably won’t be worried about them:
- You don’t have access to the private key, which means you can’t use the same certificate elsewhere.
ACM is currently only available in theACM is currently available in all major AWS regions[footnote]As of this update (2016/06/07), ACM is available all regions except US GovCloud and China Beijing)[/footnote].us-east-1region.- You can’t use ACM certificates across regions (with the exception of CloudFront, which doesn’t have a region — note that CloudFront ACM certificates must be located in the
us-east-1region, though.).
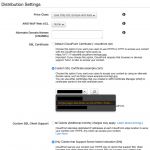
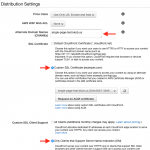
So, I decided to test it out on a silly little CloudFront distribution I have running I made for a blog post as a demonstration of how you can use S3 and CloudFront to serve a single-page JavaScript app with “proper” URLs.
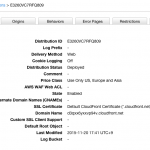
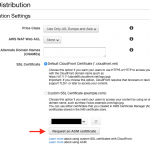
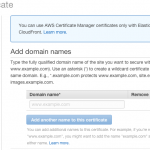
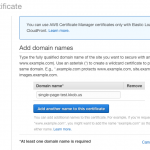
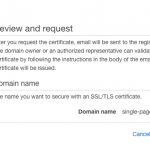
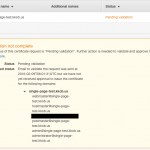

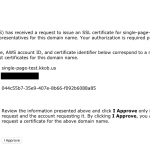
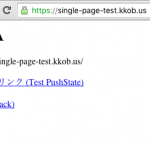
Test it out for yourself: